In April 2022, during the Shanghai lockdown, the government's harsh measures sparked a widespread online protest. As excpeted, the censorship system incorporated by Chinese internet companies and the government censored and blocked nearly every post. This made me curious about how the censorship system works, and if there is any way to circumvent it.
To start, we must first understand how the censorship system operates within a larger context. After researching numerous online resources, I found three articles that are invaluable for this purpose.
- How Xiaohongshu Censors “Sudden Incidents”
- BBC Chinese: Inside China’s Internet Censorship – A Former Inspector’s Experience
- I helped build ByteDance's vast censorship machine
Based on their description, I created a flowchart to help me understand the big picture. After examining each workflow, it becomes clear that this system heavily relies on machine censorship. Therefore, circumventing machine censorship is the essential step in circumventing the entire system. To do so, it is crucial that we understand how it works. The question is, how can we gain such knowledge? The answer lies in using the very same systems. Social media companies are obligated to censor political content in accordance with government regulations. To accomplish this, these companies often seek the services of cloud providers like Alibaba or Tencent who specialize in developing the so called content moderation systems. For instance, Tencent YouTu Lab developed such systems, and their website indicates that Xiaohongshu, the company mentioned in the document above, is one of their clients.
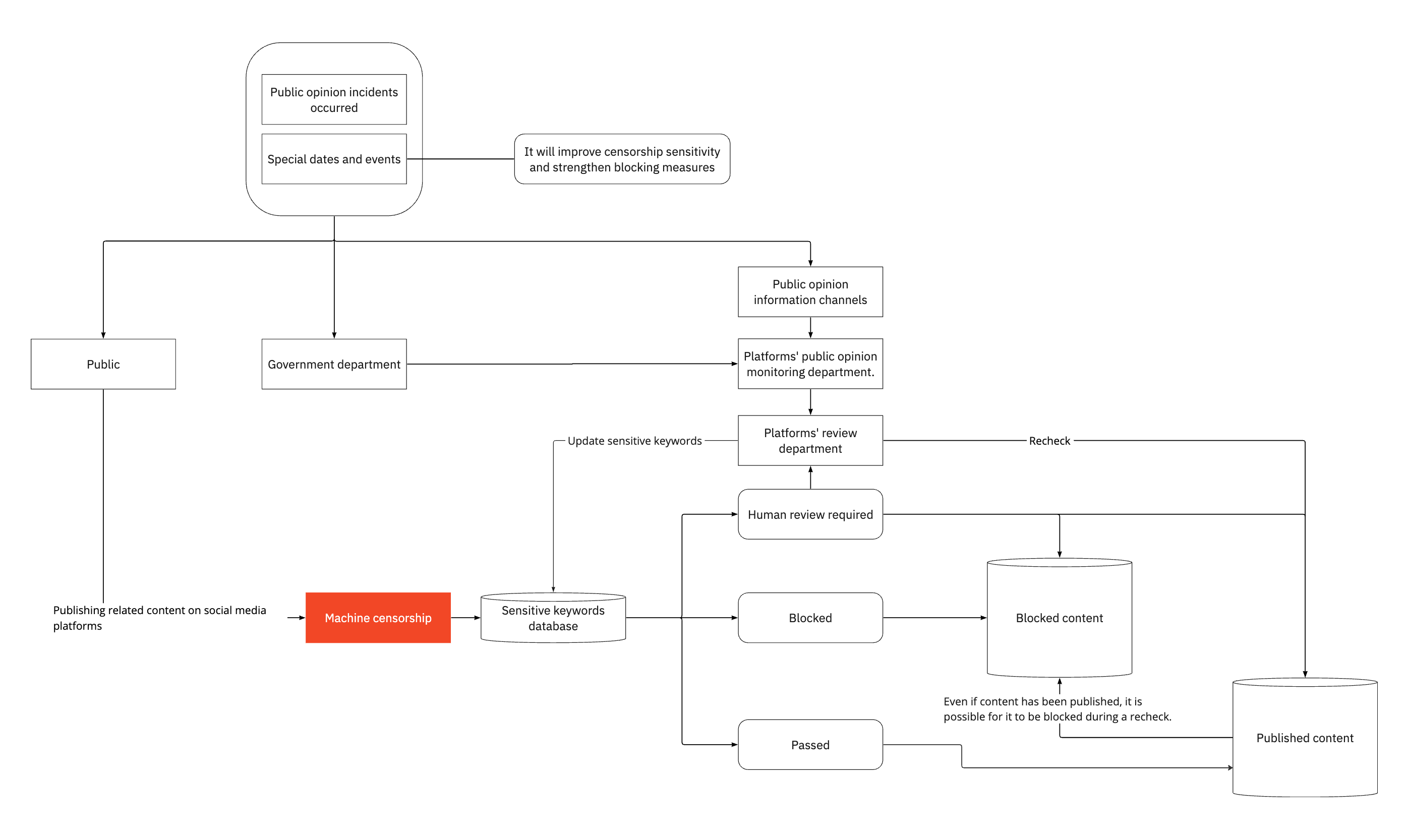
Tencent's content moderation system is a machine censorship tool that handles an extensive range of content, including images, videos, audios, streaming media, and text. Many organizations employ these systems, and they can be accessed publicly via APIs. Studying these APIs can assist us in developing a better understanding of how the censorship system operates.
Let's try one of these APIs. By sending images with various content to the API, the system will return results that indicate whether the content should be blocked. The API will also identify the specific content that led to the decision. The key components from these results are as follows:
- Suggestions by the system: pass, human review required, or blocked
- Categories of being blocked or human review required: political, ads, gambling, or sexual, etc.
- Content of being blocked or human review required:
- Sensitive Keyword: Words that the machine considers sensitive in the given text.
- Sensitive Entity: Some entities, such as public figures, weapons, and buildings, are sensitive and should be censored.
For example, the following content has sensitive keywords that could prompt the system to suggest blocking the content:
“河南乡镇银行爆雷持续发酵,一千多储户郑州维权遭驱散多人受伤。” (Translation: The bankruptcy of Henan rural banks in townships continues to ferment. More than one thousand depositors in Zhengzhou were dispersed while seeking their rights, resulting in several injuries.)
The sensitive keywords are “河南&爆雷” and “持续发酵” (Translation: “Henan & bankruptcy” and “continues to ferment”).
According to the results, the content moderation system tells us exactly why the content is blocked. Therefore, we can try to fool the machine by making it fail to recognize certain keywords or entities in the given content, allowing us to circumvent the machine censorship layer. You may wonder how we know how machines "recognize" this content. We surely know. Since these technologies are from academia and are publicly available. Furthermore, companies such as Tencent have openly shared papers and articles detailing how these systems operate.
Let us delve into the machine brain of censorship systems. Take recognizing sensitive keywords, for instance. Not only can the system detect sensitive keywords in texts, but by utilizing state-of-the-art machine learning algorithms such as text recognition and speech-to-text, it can extract text from images, videos, and audio to analyze if it must be censored. Moreover, these systems also incorporate other technologies to determine whether a text should be blocked. Tencent claims to use fastText technology, a text classification algorithm developed by Meta, to classify if a paragraph of text should be categorized as blocked.
If we successfully obscure the sensitive keyword within the given text, the machine will not consider blocking it. As previously mentioned, various types of media exist, including text, pictures, audio, video, and streams. While altering audio, video, and streams can be challenging, modifying text is relatively straightforward. We may alter text by transforming it into an image and changing its appearance to circumvent the machine. Even with the alteration, people should still be able to read it fluently.
The technology utilized to extract text from images is known as OCR, and modern OCR systems are trained on printed fonts. Consequently, using glyphs that differ from those present in the training data could help circumvent machine censorship. Since the machine has not encountered such glyphs, it may fail to recognize them. Unfortunately, we discovered that the algorithm can still recognize various glyphs. To bypass it, we utilized a calligraphy font. However, such text would be challenging for humans to read.

Is it possible to create text that humans can read but machines struggle to understand? Absolutely! We encounter CAPTCHAs daily, which stands for Completely Automated Public Turing test to distinguish between Computers and Humans. CAPTCHAs are commonly used to differentiate between human and machine users, and they are designed to be unrecognizable to text recognition systems. By using CAPTCHAs, we can bypass machine censorship systems while maintaining readability.
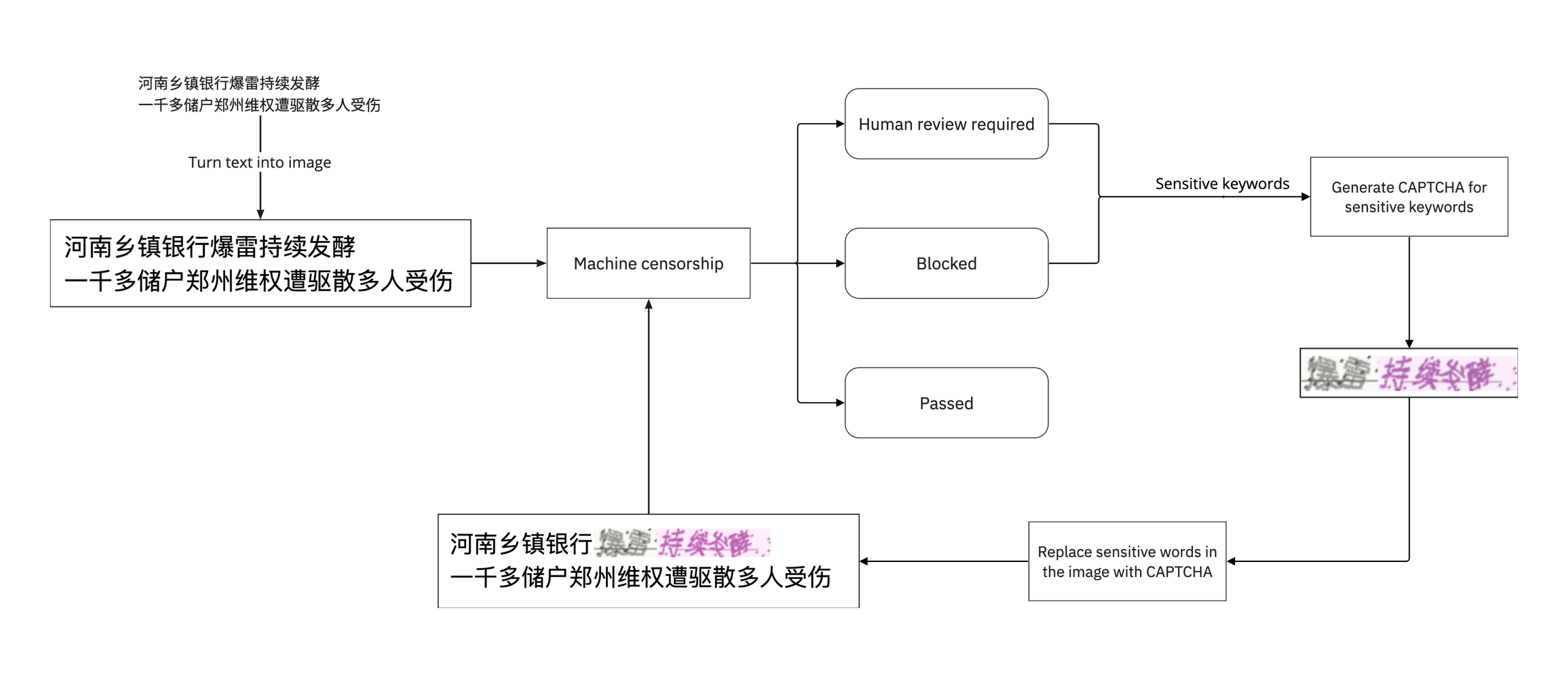
To implement this, follow these steps:
- Turn the words into images.
- Utilize the APIs provided by a cloud service to identify sensitive keywords.
- Generate CAPTCHAs for those keywords.
- Replace the original text with CAPTCHAs.
- Send the modified image to APIs and check the result.

How effective is this method? We collected 1424 articles from the Internet and converted them into images. We then sent these images to the content moderation system, 982 of them as blocked due to political reasons. The system identified 1394 sensitive keywords in those articles. With the use of CAPTCHAs, only 494 of the articles were identified as blocked, and the number of identified sensitive keywords reduced to 383, an 71.6% reduction. Looks great!
| Without CAPTCHAs | With CAPTCHAs | Changes | |
|---|---|---|---|
| Number of Blocked Articles | 982 | 494 | -49.7% |
| Number of Sensitive Keywords Found | 1394 | 383 | -71.6% |
| Frequency of Sensitive Keywords | 5889 | 965 | -83.6% |
Throughout the process, I acquired a deeper comprehension of text recognition technologies and explored other techniques to avoid the system. Here are some alternative approaches.
Other CAPTCHA Techniques
We only use some of the techniques to generate CAPTCHAs, but there are many other techniques that can also be utilized.
Nearby-Character Obscuration
Text recognition systems have a lower likelihood of accurately identifying obscured characters surrounding the text. Since these systems read line by line, converting nearby characters into CAPTCHAs can deceive the machine. Based on our testing, this method has proven to have a higher success rate in fooling the machine. Please refer to the image below for a demonstration.

Text Direction Obfuscation
A pre-processing algorithm is needed to identify the text direction before the machine "reads" the text. In Chinese, characters can be formed into both horizontal and vertical lines. Therefore, the pre-processing algorithm needs to identify whether a line is vertical or horizontal. We adjusted the spacing between characters to trick the machine into thinking a horizontal line is vertical. This resulted in the machine reading the text in disorder, making it unable to recognize sensitive keywords.

Character Grouping
Similar to fooling the pre-processing algorithm, we group multiple characters into one line to fool the machine by the same principle that the machine reads line by line. See the image below for examples.

Other Ways
Rotating, flipping, or translating simplified Chinese characters into traditional Chinese characters does not work. The machine will recognize those texts with great accuracy.
The above methods are relatively easy to implement. However, while researching ways to fool machine learning algorithms into recognizing text, I came across the concept of an adversarial attack, which is a great way to fool machine learning algorithms. With an adversarial attack, we can fool a neural net into recognizing a panda with only 57.7% confidence as a gibbon with 99.3% confidence. Further research led me to a paper published by Tsinghua University that showed how to fool the machine using adversarial attacks in recognizing text using watermarks. But the issue is that both of these attacks are white-box attacks, meaning that the algorithm has complete knowledge of the text recognition model. In a real-world scenario, we would have no such knowledge. However, the use of machine learning algorithms to circumvent censorship systems looks promising.


This study is purely for research purposes and driven by curiosity, and I hold no political bias. However, I hope to see more Chinese characters that have not been censored by the system. Finally, I would like to share a few words that I am glad to know are actually sensitive keywords.
- 我们纳税人 (We taxpayers)
- 八的平方 (The square of eight)
- 群体事件 (Mass incidents)
- 舆情发酵 (Public opinion fermentation)
- 一骂国民党&新闻尽撒谎 (Damning the Kuomintang, as the news is full of lies)